[PDF]
TL;DR;
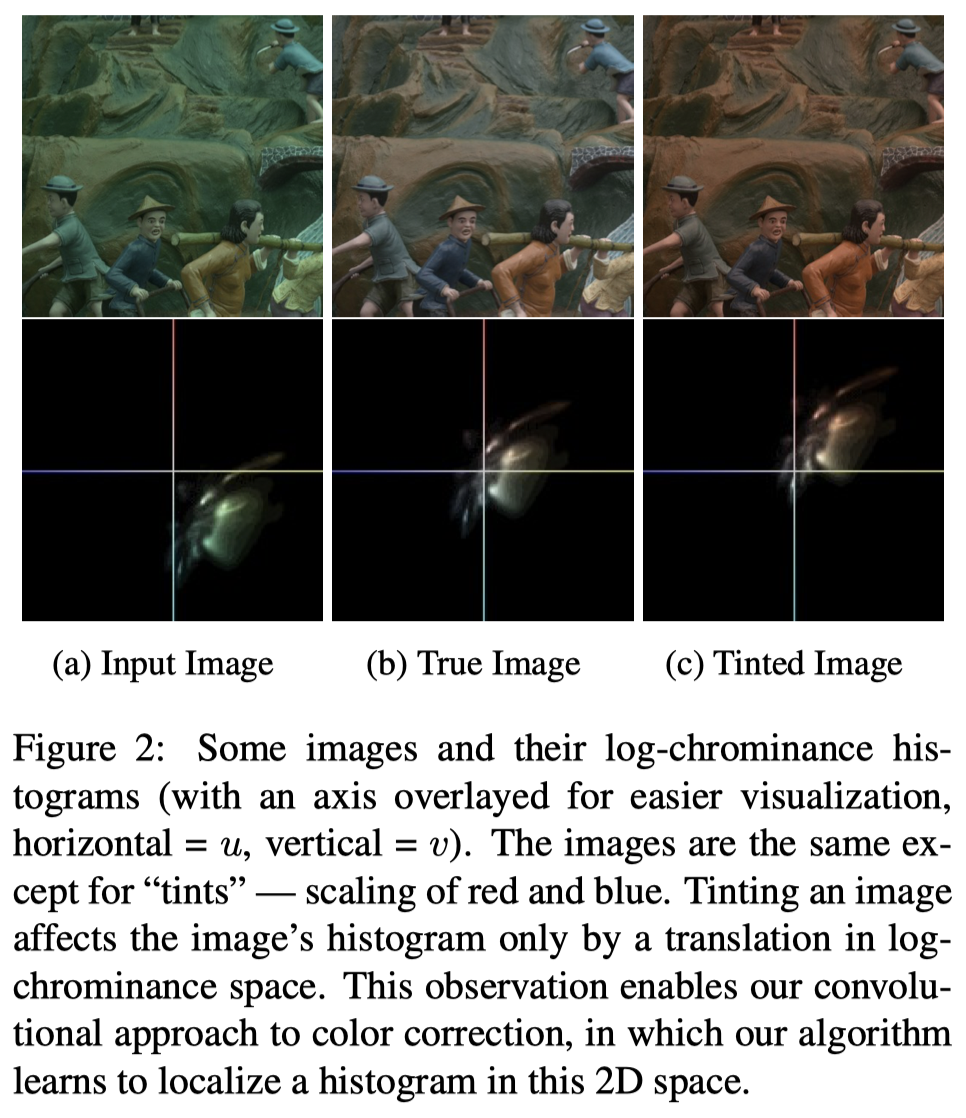
- pixel = reflectance * illumination 을 따르는 이미지 모델 하에서, RGB space 의 WB operation은 log chromaticity space에서 히스토그램의 평행이동과 동일하다
- 이미지로부터 log chromaticity histogram을 생성한 뒤, Filter Convolution을 통해 조명값을 추정한다
- Filter Convolution 결과는 이미지와 동일한 해상도를 가지며, 각 위치의 log chrominance가 GT 조명벡터일 Score를 의미한다
- Filter는 트레이닝 데이터로부터 학습되며, 이러한 방법론은 Discriminative 방법론이다
- 필터를 학습할 때 사용되는 loss function은 컨볼루션 결과에 Softmax를 적용하여 각 위치의 값을 조명추정에 대한 확률값으로 나타내며, 해당 확률값에 '각 위치의 조명값과 GT사이의 Angular Error'를 곱해 minimize한다. 필터는 L2 normalization으로 규제
- 이미지 사이즈와 동일한 필터 크기는 연산량과 메모리에 부담되므로 7 layer image pyramid에 대해 각 레이어별로 5x5 사이즈 필터를 학습하고 컨볼루션 결과값을 다시 upsampling하여 합쳐준다. 이는 계산속도를 빠르게 하며 큰 크기의 필터보다 여러 이점이 있다
- 이미지 한장 대신 동일한 이미지를 여러 방법으로 조작해서 4개의 augmented image를 사용하여 판단한다

논문에서 가정하는 이미지 모델. 다양한 변수는 모두 제거하고 오로지 Reflectance와 Illumination의 곱으로 표현한다.
이러한 이미지 모델 하에서 WB 과정은 모든 픽셀이 동일한 비율(조명값을 제거하는 방향)로 조정되므로 log chrominance space에서 히스토그램의 평행이동으로 표현된다.
이미지 내에서 Saturated Pixel은 없다고 가정하는 것을 보아 WB 진행 전 Saturation은 제거하는 게 일반적인 듯.
이 논문에서는 Generative 방법론이 아닌 Discriminative 방법론을 사용함.

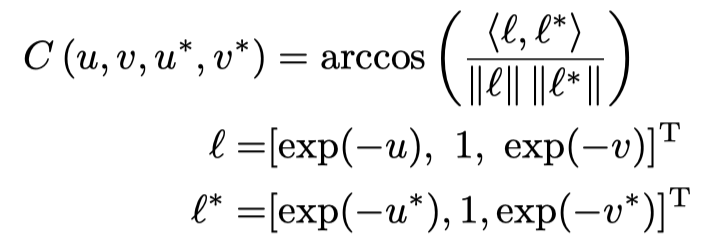
필터는 트레이닝 데이터를 사용하여 위의 loss를 줄이도록 학습되는데, L2 normalization term과 Discriminative Loss term의 합이다.
P는 이미지의 히스토그램에 필터를 컨볼루션한 뒤 Softmax를 적용한 것으로, 각 log chormaticity 위치가 GT Illumination일 확률이다.
C는 각 log chromaticity 위치에서 GT illumination과의 Angular Error이다.

Generative하게 학습된 필터와 Discriminative 하게 학습된 필터를 비교한 결과, D방법론이 더욱 풍부한 표현을 학습하며, G는 단순히 Gray World 가정에 근거한것과 같은 학습 결과를 보인다.
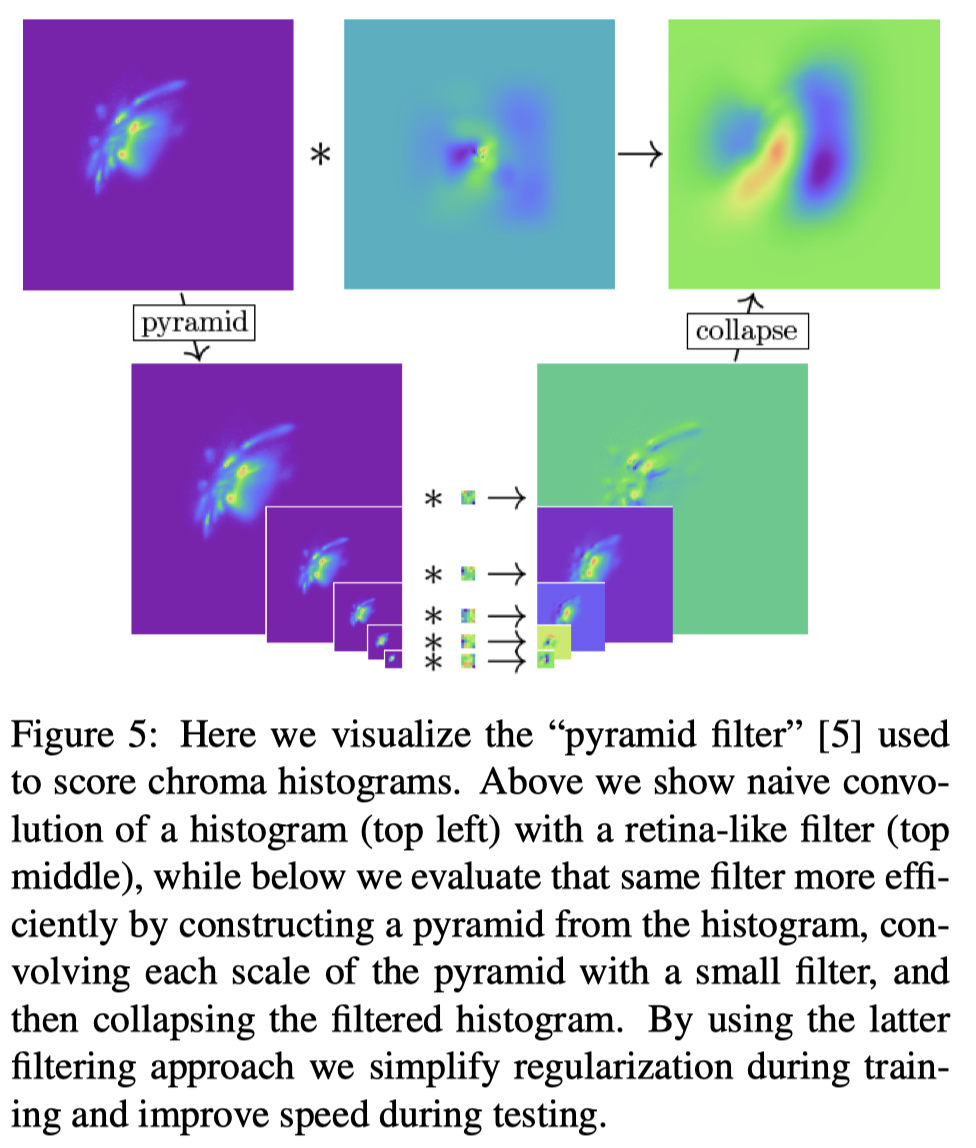
이미지와 동일한 해상도의 필터를 통과시키는 것은 연산량 면에 있어서 cost가 크므로, pyramid image의 레이어별로 5x5 필터를 각각 학습시킨 뒤 convolution result를 upsample해 합치는 방법을 사용했다.
