간단요약 : 전체 비디오를 N등분, 그 N등분 내에서 랜덤한 스니펫(클립) 샘플링
-> 그 스니펫들을 Spatial&Temporal 네트워크 두개에 통과시킨 후 모든 스니펫 결과들을 합쳐서 결과를 내는 모델
1. Introduction
이 논문에서 제시하는 기존의 ConvNet이 즉시 비디오레벨의 action recognition에 적용될 수 없는 이유는 두가지이다.
액션 비디오에서는 long-range temporal structure이 중요하다. (동작 전체의 긴 맥락을 이해하려면 매우많은 프레임을 다 보고 이해해야 함) 하지만 기존의 컨볼루션 필터와 그를 활용한 네트워크들은appearances 와 short-term motions 에만 집중하기 때문에 이런 부분에서 기대에 미치지 못하는 성능을낼 수밖에 없다.
따라서 이러한 부분에 대처하기 위해, 전체 비디오에서 사전 정의된 샘플링 간격대로 조밀하게 클립샘플링을 한 뒤 이 클립들을 활용하는 방안이 제시되었으나, 계산량이 너무 많고 maximal sequence length를 넘는 비디오에 대해서는 중요한 정보를 놓칠 수 있다는 치명적 단점이 있다.
-> 어떻게 하면 long-range temporal structure를 잡아낼 수 있는 효율적 모델 구조를 설계할 수 있을까?
기존에 존재하는 비디오 데이터셋의 크기와 클래스 다양성 부족 문제 때문에 트레이닝이 힘들며 과적합의 문제가 발생할 수 있다.
-> 제한된 데이터셋으로 ConvNet을 잘 학습시킬수 있는 방법은 없을까?
또한, 연속된 프레임의 경우 거의 변화가 없으므로 dense frame sampling은 쓸모없다는 것을 발견, 따라서sparse sampling을 진행했다고 함. 이런 방법을 사용할 경우 계산량이 매우 줄어들게 되며, 이러한 temporal segment network의 잠재능력을 확인하고자 최근에 발표된 굉장히 깊은 ConvNet 구조를 베이스라인으로 차용했다.
또한 적은 데이터셋에서 기인하는 문제를 해결하고자 1) cross-modality pre-training, 2) regularization, 3) enhanced data augmentation 등의 방법을 사용했다고 한다. 그리고 입력 modalities 도 1) single RGB imgae, 2) stacked RGB difference, 3) stacked optical flow field, 4) stacked warped optical flow field 의 4가지 경우를 테스트해보았다고 한다.
본 논문이 실험한 데이터셋은 UCF101과 HMDB51 이라고 한다.
2. Action Recognition with Temporal Segment Networks
a. Temporal Segment Network의 구조
인트로에서 이야기했듯이 기존 two-stream ConvNet의 문제점은 long-term temporal structure를 학습할수 없다는 점이다.
단일 프레임이나 짧은 스니펫에서는 이러한 정보를 확인하기 어렵다.
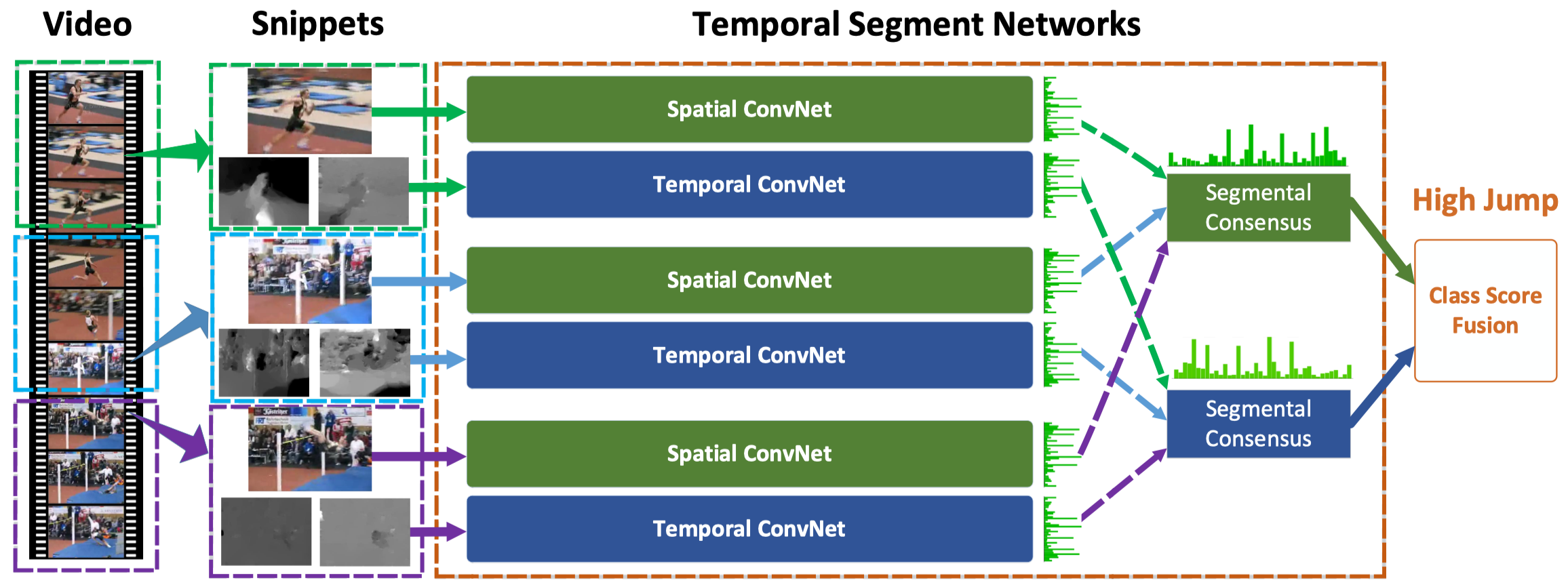
우선 여기서 제시하는 TSN은 전체 비디오의 visual information을 활용하기 위해 역시 기존 방법론을 어느 정도 차용해 Spatial ConvNet과 Temporal ConvNet으로 이루어져 있다. TSN은 전체 비디오에서sparsely sampled된 스니펫들을 이용해서 임시 예측을 거치고, 그러한 스니펫들에 대한 예측 결과를 하나로 합쳐 전체 비디오에 대한 레이블을 내놓게 된다. 기존의 two stream 방법론에서는 모든 스니펫들에 대한 모든 classification 각각을 바로 비디오 전체에 대한 label과 비교하여 loss로 활용했는데, TSN은그러한 정보를 하나로 합치는 과정이 추가되었다.
TSN의 동작 과정을 간단하게 살펴보면, 아래와 같다.
1. 비디오 전체를 균일한 길이를 갖는 K개의 Segment로 나눈다 (이 논문에서는 K=3 사용)
2. 각 Segment에서 랜덤하게 snippet을 샘플링한다
3. 각 snippet에 대해 동일한 네트워크 (가중치 공유) 를 통과시켜 모든 클래스에 대한 class score를 뽑는다
4. 모든 snippet에 대한 class score를 합쳐 하나의 레이블을 추론하는 Segmental Consensus
function G (이 논문에서는 그냥 클래스별 점수의 평균 중 Maximum을 고르는 함수) 를 통과시킨다
5. G가 생성한 클래스별 score를 이용해서 하나의 output을 내놓는다 (일반적으로 Softmax 사용)
위의 방법을 통해 모든 스니펫으로부터 backpropagation이 가능하여 모델을 최적화하는 구조를 갖고, gradient 식의 구조상 G함수가 뱉는 consensus 결과값이 모든 스니펫 prediction을 한번에 이용하여 유도되는 구조를 갖는다. 따라서 이러한 방법을 통해 TSN은 짧은 스니펫 하나하나에 영향을 받기보다는, 비디오를 전체적으로 보고 판단하는 모델이 될 수 있다.
b. 제한된 데이터셋으로 TSN을 효과적으로 학습시키기
네트워크 구조
기존 object recognition 태스크에서는 깊은 신경망일수록 더 나은 결과를 보여주었다. 하지만 Two-stream Network는 상대적으로 얕은 네트워크 구조를 갖고 있다. 따라서 이 논문에서는 BN-Inception 의 정확도와 효율성을 고려하여 이를 기본 Building Block으로 사용했다고 한다. 오리지널 Two-stream Network에서처럼 spatial stream ConvNet은 단일 RGB 이미지에 대해 작동하고, temporal stream ConvNet은 consecutive optical flow field를 입력으로 받는다.
네트워크 인풋
조금 더 다양한 input modality를 탐색하고자 두가지의 추가적인 modality를 실험해보았다고 한다. 단일 RGB는 한 순간의 spatial information을 잘 담고 있지만, 앞뒤 프레임과의 관계를 고려한 contextual information을 담고 있지는 않다. 따라서 motion이 발생한 지점에서 두드러지는 값을 갖는 stacked RGB difference 를 사용하고 실험해보았다고 한다.
기존에 temporal stream ConvNet은 optical flow field를 사용했지만, 이는 카메라의 움직임 등에 의해집중하고자 하는 사람의 움직임만을 바라볼수는 없게 된다. 따라서 카메라의 모션을 상쇄하는 방법론을 적용한 optical flow 추출 기법인 warped optical flow field를 추가적인 input modality로 사용/실험해보았다고 한다.
네트워크 트레이닝
제한된 양의 데이터셋을 통해, overfitting을 방지하면서 효율적으로 ConvNet을 학습시키기 위해 많은기법들을 적용했다.
- Cross Modality Pre-training
많지 않은 양의 트레이닝 데이터를 갖고 있을 때, pre-training은 deep ConvNet을 효율적으로 초기화하는 방법임이 널리 알려져 있다. TSN의 spatial network같은 경우 RGB 이미지를 입력으로 받기 때문에, 이미지넷을 이용하여 사전 학습을 진행하는 것은 굉장히 자연스러운 방법일 것이다. 다만, optical flow field나 RGB difference같은 경우 RGB 이미지와는 다른 방법(변화에 집중)으로 비디오 데이터의 시각적 측면을 파악한다. 따라서 본 논문에서는 RGB 모델을 이용해서 temporal network를 초기화하는 cross modality pre-training을 제시한다.
먼저, optical flow의 범위를 RGB 이미지 픽셀의 범위와 동일하게 0~255의 값으로 만들어 준다. 그런 다음, RGB를 대상으로 했던 모델의 첫번때 convolution layer를 수정해서 optical flow를 input으로 받을 수 있도록 수정한다. 정확히는 픽셀별로 RGB 채널에 해당하는 가중치를 평균 낸 뒤, 모든 채널에 복사한다. 이 방법을 통해서 첫번째 레이어에 대해 효율적으로 초기화를 진행했다고 한다.
- Regularization Techniques
BN은 효율적인 정규화 방법이며 모델의 수렴 속도를 빠르게 하지만 적은 데이터셋에 대해 과도하게 적용하다 보면 overfitting 문제가 발생할 수 있다. 따라서 RGB->Optical flow로 변화하는 첫번째 레이어에서만 mean과 variance를 추정하여 효과적으로 대응할 수 있게 하고, 그 뒤의 BN레이어는 모두 freeze 시켰다고 한다. 또한 오버피팅 문제를 피하기 위해 BN-Inception 모델의 모든 global pooling 레이어 뒤에 dropout 레이어를 적용했다고 한다. Spatial stream ConvNet에서는 p=0.8로 설정했고, Temporal stream ConvNet에서는 p=0.7로 설정했다고 한다.
- Data Augmentation
원래 기존의 Two-stream ConvNet에서는 랜덤 크롭핑, 수평 반전이 사용되었는데, 본 논문에서는 추가적으로 2가지의 방법을 더 사용함.
corner cropping 과 scale jittering 이라고 함.